Devlog #4 - Fast Collisions for Large Editable Vehicles
What if you could store cargo in your space ship and fly the space ship inside a rotating space station, which you built using hundreds of thousands of bricks?


Welcome back to our fourth devlog! Today we'll take a deep dive into our new collision detection system for brick grids, capable of scaling up to thousands of dynamic objects colliding with huge editable vehicles and anything inbetween.
We'll shine lights behind the scenes, all the way down to the custom spatial indices, the memory management, and how it all performs. Buckle up!
Watch this physics demo first to get a sense for the scale we're going for:
Overview
The post ended up becoming so absurdly long that I needed to give it an index.
Introduction
Potential Solutions
Compounds and Aggregates in PhysX
Voxel-Based Concave Collisions
Custom Compound Shapes in PhysX
Choosing a Dynamic Spatial Index
Bounding Volume Hierarchies
K-D Trees and Friends
Octrees
Loose Octrees
OctoBVH: Improved Loose Octree
Tight Bounds Hierarchy
Force-Splitting Overfilled Nodes
OctoBVH vs Loose Octree
OctoBVH Memory Layout
Virtual Memory Pools
OctoBVH Queries
Overlap Query
Raycast Query
Sweep Query
Contact Generation
Collision for Editable Structures
Convex Approximation From OctoBVH
Convex Simplification to Box
Results for Real World Builds
Fixing Unreal Engine Performance
Batching Render Transform Updates
Speeding up MoveComponent
Extra Goodies
Faster Brick Loading
Reduced Return to Menu Delay
Reduced Client Memory Usage
Reduced Server Memory Usage
What's Next for Brickadia?
Introduction
You might think: "What are we doing here? Didn't we see physics already?"
Indeed, we have shown you some clips of physics objects in the game before. But what you probably didn't know is that previously, we really only supported approximating each brick-built structure as a single bounding box around it.
There also wasn't any collision between ragdolls and movable grids at all.




Now... that's not very satisfying at all, is it? I might even consider it unplayable.
What we really want to have for a game like ours is concave collision detection. Before we go crazy over engineering this, we should take a look at whether other people have already solved this problem in some way that we could make use of.
Potential Solutions
We aren't the first developers who want to have detailed collisions against concave objects like planes that were built at runtime. Indeed, we found several possible approaches in use elsewhere:
Compounds and Aggregates in PhysX
The physics engine we use already supports a concept called aggregates. One of the suggested use cases is a single object with a large number of shapes attached to it, doesn't that sound exactly like what we need?
Unfortunately, aggregates are not scalable enough for the builds typically seen in Brickadia. They still require updating and spatially sorting all shapes in the compound every tick, so if you build space ships out of a hundred thousand bricks and try to fly a smaller one inside, the game becomes unplayable.
This was actually the first solution I tried, and it would have supported two-way concave collisions such as a chain of rings if it worked. On to the next!
Voxel-Based Concave Collisions
A few other building games that allow constructing large vehicles are using voxel based collisions. Examples of this include games like Space Engineers or maybe Starmade. There is also a very detailed and technical explanation of voxel based collisions in Teardown here.
However, there's one thing all these games have in common that we don't have, which is that you build stuff out of (mostly) uniformly sized voxels!
In Brickadia, we must support everything from microbricks at 1/5 the size of a stud to massive ramps that are a hundred studs wide, arches, cylinders, and other round shapes, the list goes on. It would be extremely difficult to sensibly represent the objects with uniformly sized voxels and still achieve good results, i.e. with smooth motion sliding down a ramp.
With the largest build being a thousand times larger than the smallest build, covering billions of cubic microbricks in volume, it also raises questions about the memory requirements of this solution. I chose not to try implementing voxel based collisions for now due to these problems. On to the next approach!
Custom Compound Shapes in PhysX
Recently, a new feature was added to PhysX: custom geometry. Basically, you can tell the physics engine that there is a shape here with some bounds and inertia values. It will then simulate its movement for you, but you have to implement everything inside yourself. Most importantly, you can provide your own implementation of generating contacts for other shapes touching it.
We can use this to implement our own large compound shape! To allow another shape to collide with it, we'd then need to have some kind of internal acceleration structure, so we can find bricks near that shape. Here is the basic idea:
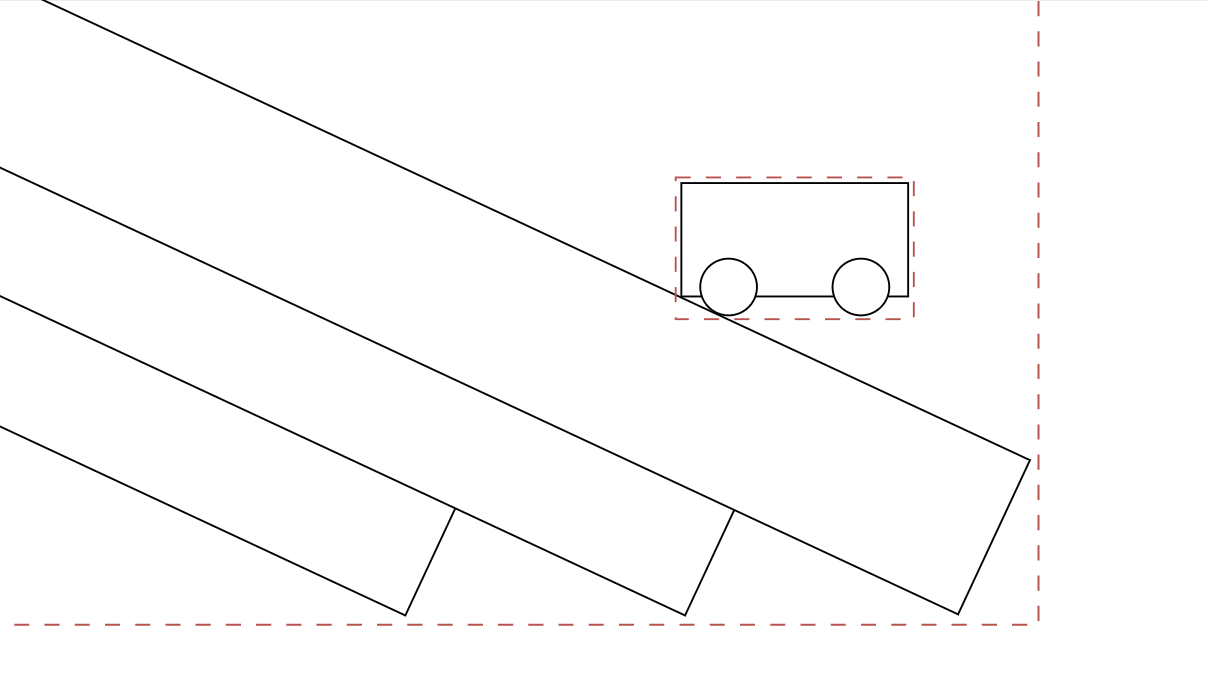
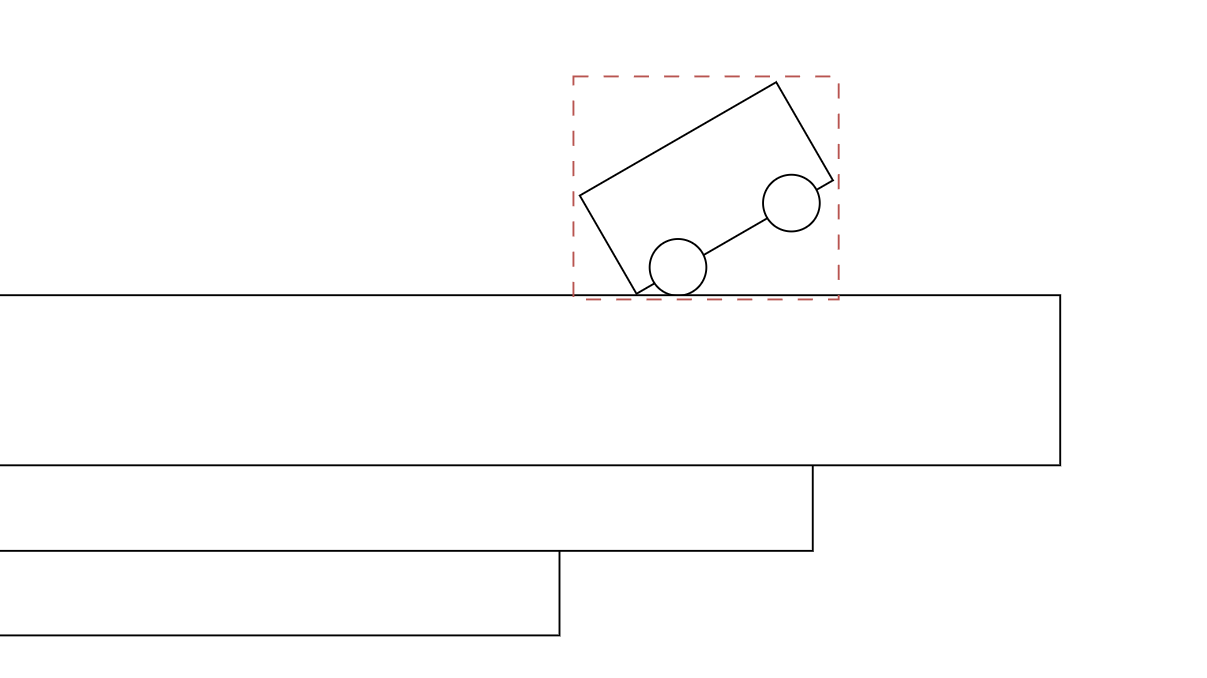
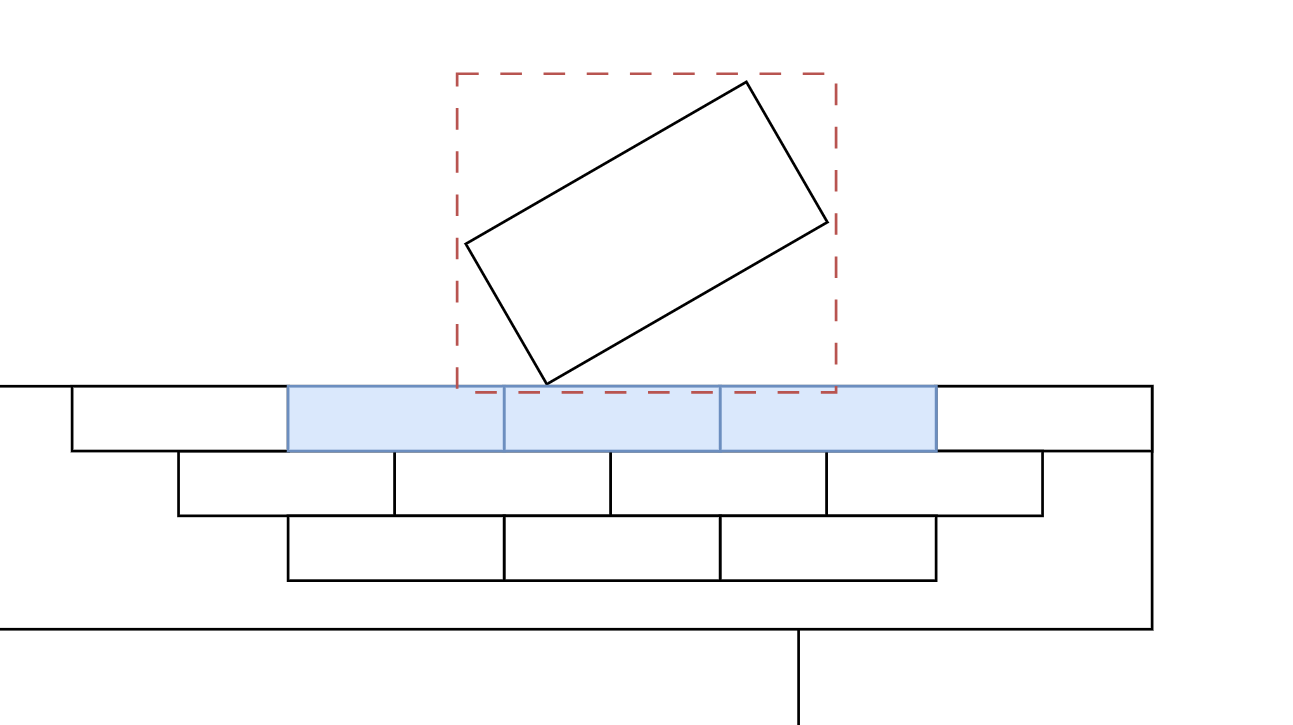
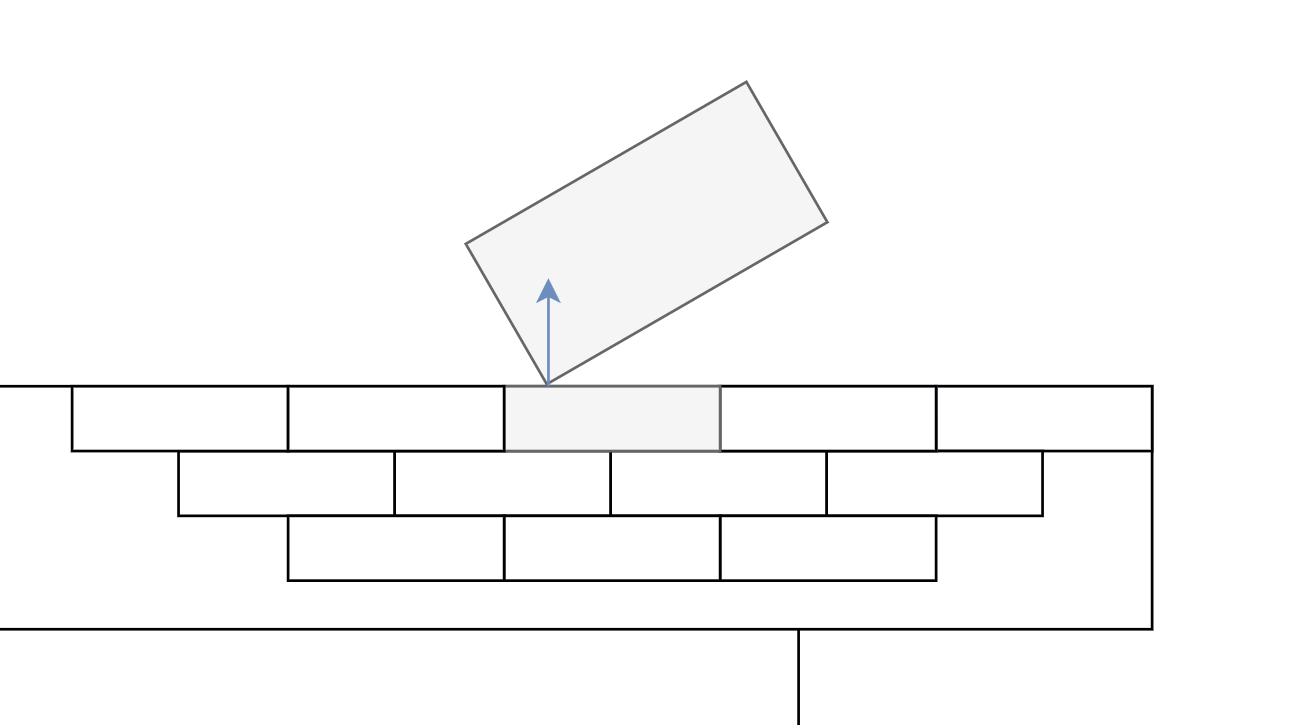
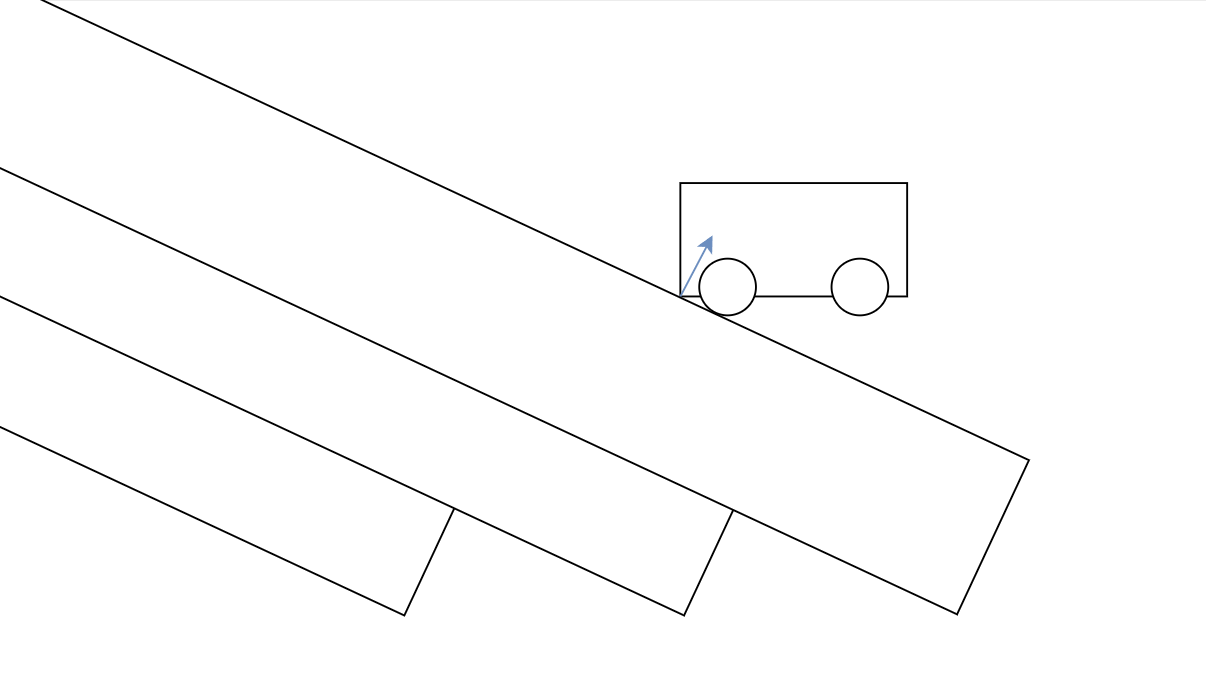
This idea covers one way concave collisions so far. That means, you could have a truck drive inside a space station with crates in its bed, but you could not make a chain of rings without some tricks. It's not quite perfect, but we don't want to let perfect be the enemy of good, do we? Supporting one way concave collisions is infinitely better than none at all, and likely to perform much better in the end.
As we'll find out later, this is more than enough for most simulations we tried to play with. It was also enough for everything you've seen in the physics trailer.
This is the option I decided to go with in the end. Let's get started!
Choosing a Dynamic Spatial Index
The most difficult part of this system is the third step where we have to find nearby bricks to detect if an incoming shape is colliding with them. We'll need some kind of spatial index that we can update as bricks are placed and removed.
To make this choice easier, let's start by listing all the things we need:
- Must be able to insert objects as bounding boxes rather than points.
- Must be able to handle objects of wildly differing sizes, such as a microbrick corner adjacent to a 500 times longer ramp.
- Must be able to handle structures with wildly unbalanced distribution of objects, such as a detailed microbrick room on top of giant cubes.
- Must be able to handle anything from small structures to huge structures with tens of millions of objects in the index.
- Must be able to insert new objects anywhere, including outside the current total bounds of the index.
- Must be able to remove any of the objects at random.
- Must be able to insert or remove thousands of objects at random places without causing a noticeable hitch, i.e. we must never require a global rebalancing or rebuild of the index.
- Must be able to do raycast, sweep, and overlap queries against the index.
There are also some things that are not absolutely required, but would be nice:
- Since you can toggle collision channels on bricks, it would be nice if we could only process regions that contain objects that we know will match the query channels, skipping everything else.
- Since you can collide large objects with extremely detailed structures, it would be nice if we could provide some kind of automatic level of detail for collisions, i.e. consider clusters of objects that fall below some size threshold as a single box and stop processing them.
- Since Brickadia is a multiplayer game, players will likely replicate bricks in different order. We want reduced detail collision detection to at least return similar results for every user, so it would be nice if there was a single "correct" index for any given set of bricks that we always arrive at regardless of what insert and delete operations occured previously.
Wew, that's a lot of requirements for this index! Let's think about some common spatial data structures and see if we'll be able to use them.
Bounding Volume Hierarchies
A BVH is basically a tree of bounding boxes, where each node represents a bounding volume that encloses a part of the build. The root node represents the entire structure, and each child node represents a smaller subset of the bricks, recursively dividing the space until each leaf node contains just a few of them.
There are several ways to efficiently create a new BVH, such as sorting objects by a space filling curve to identify leaves and then constructing a hierarchy of nodes above those. Unfortunately, trying to modify a BVH by inserting new objects or removing existing ones is very difficult and would cause it to slowly become less efficient over time as it gets more and more unbalanced. We would then need a global rebuild to fix our BVH. This is clearly not the way to go for bricks.
K-D Trees and Friends
Another common spatial index is a k-d tree, or some variation of it. It is also a tree like the BVH, except that we build it by recursively dividing the build in half with an axis aligned plane until we run out of bricks to split. A k-d tree can be adapted to store bounding boxes by storing the min/max values on each split. However, this is again not useful as we would have to either constantly rebuild the tree or constantly rotate nodes trying to keep it balanced.
Octrees
An octree is essentially a tree of subdividing cubes. We start by containing the entire scene in a large cube, and recursively subdivide the cube into 8 smaller cubes until all cubes only contain a small set of bricks. The main benefit this tree has over the other ones is that it has a well defined regular structure, i.e. we do not have to re-balance it at any point.
However, an octree can only contain points or voxels, as objects have to fit within the axis aligned cubes for queries to work correctly. So we cannot actually use it.
Loose Octrees
Not all is lost though, because it is easy to adapt the octree into a loose octree. All we need to do is assume each cube is actually twice the size while querying the tree, and then make sure to leave objects that are too large to fit into smaller subdivided cubes in the higher levels of the tree.
We can quickly check if this index meets all our requirements from further up:
- Objects as bounding boxes - yes, that's the point.
- Wildly differing sizes - yes, they will live in different levels.
- Unbalanced distribution - yes, will subdivide more in detailed regions.
- Millions of objects in the index - yes, it will take lots of nodes though.
- Inserting objects outside the bounds - yes, can add a larger outer cube.
- Able to remove objects - yes, collapse cubes when empty.
- No global rebuild or balancing - yes, we don't need this ever.
- Raycast, sweep, overlap queries - yes, we can implement these.
This seems promising so far! But what about the "nice to have" things we want?
- We could skip processing regions containing only objects that don't match the query filter by propagating a bitmask for query responses along with each node. For example, if all objects in some subtree don't collide with players, we can store on each node that this is the case, and skip processing that subtree entirely in queries from players.
- We can provide some kind of automatic level of detail for collisions by simply not recursing into subtrees whose cube is too small. We could then consider that entire tree to just be a solid cube to collide against.
- Since the octree has a well defined regular structure, we can build the same octree regardless of the order the elements came in. We'll need to make sure that we apply the same rules to insertions and removals. For example, if we split a cube into smaller ones on having 9 or more bricks in it, then we must also recombine a split cube back into a single one once it has 8 or less bricks in it.
Now that we know which index to use, let's get into the fine details of how we can use this for our purposes, how we store and query it efficiently, etc.
OctoBVH: Improved Loose Octree
The loose octree has many significant disadvantages. Here's what it looks like if we implement it the most basic way. Black boxes are pure intermediate nodes, grey boxes are intermediate nodes with elements, and purple boxes are leaf nodes with elements. Empty leaves are not shown.


The first thing you'll notice is that those doubled bounds to contain large bricks are absurdly massive! We're going to be searching a lot of unnecessary subtrees for every query.
This immediately becomes visible in the code path for loading a save, where we're running a lot of tree queries to find potential overlapping bricks, hide adjacent faces, etc, interleaved with adding new bricks to the tree.
For fun, I added a bit of extra code to count up the number of box intersection tests and loaded a few large save files I had. The results are:
- Brick Party (~2 million bricks): 2,103,969,999 tests
- North Pacific (~4 million bricks): 3,562,837,061 tests
- Midnight Alley (~4 million bricks): 4,878,939,315 tests
There's another, more tricky problem: many of the bricks do not actually lend themselves well to being organized into subdividing cubes. For example, consider the visualization for this stack of baseplates.

We can see that the node is grey, not purple. It tried to subdivide it further, but then got stuck since the plates are too large to actually fit in the smaller nodes. We sometimes end up with a large amount of elements in a single node, which destroys query performance since every single element will have to be checked.
I found a few improvements we can make to our index though. Let's see!
Tight Bounds Hierarchy
Specifically, what if we just didn't query against those huge bounds? We could start at the leaf nodes, compute actual bounds around the elements in them and store them on the leaves. Then propate these up the hierarchy, each intermediary node gets a bounding box around those of its child nodes and any large elements contained within it.
Here's a sketch of what that change would look like for a single subdivided node in 2D. The loose bounds of each node are actually overlapping each other.
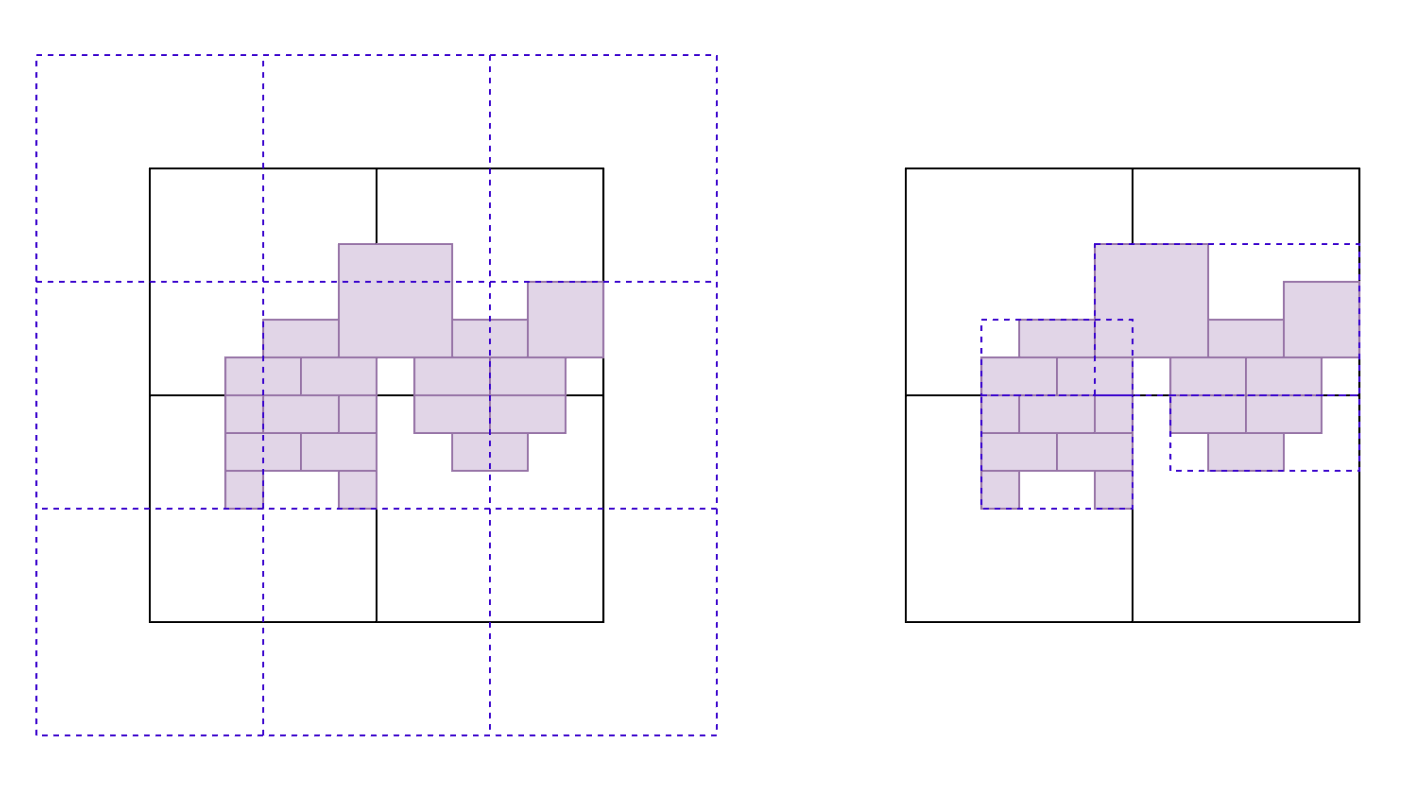
That seems like a massive improvement! Let's implement this straight away. To store the bounds on each node - at the most simple encoding this will just be two vectors with 3 dimensions for the min and max points. We'll need to store an additional 6 floats, so 24 bytes. Essentially negligible.
We can see how this change results in significantly less dead space around the actual objects. Compare these to the previous ones - the bounds of node clusters actually visually follow the overall shape of the build now.


However, we haven't yet solved this worst case of inserting many flat objects:

Force-Splitting Overfilled Nodes
Now that our nodes store their own explicit bounds, we can also solve the case of too many large flat objects. Previously, we had made the bounds smaller when they didn't need to be that large. What if we made them larger in some cases?
The idea is to relax the condition that objects can only be inserted in nodes that are larger than themselves. For example, if we detect that a node has too many objects in it even after attempting a normal split, we could force-split it and move those objects to the children regardless. The code for computing tight bounds around our nodes will ensure queries continue to work properly:
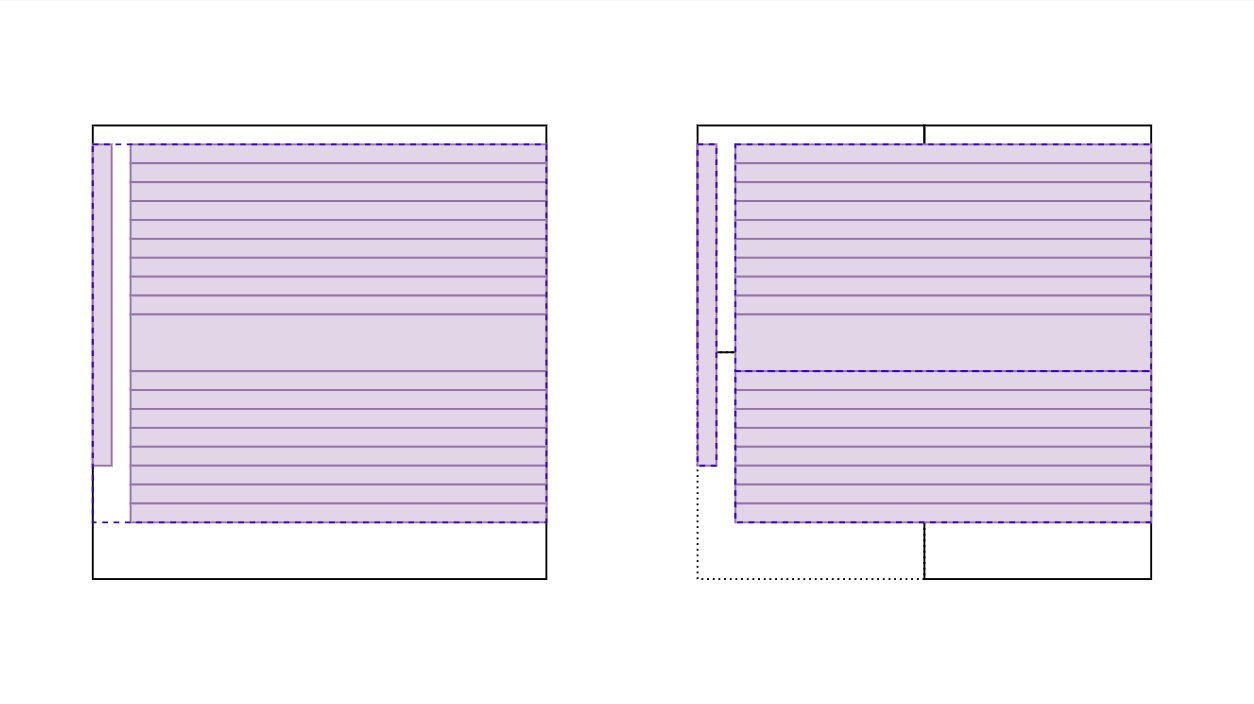
In practice, I found it extremely difficult to properly revert these force splits on removing objects from the tree. This was definitely the hardest part of this entire project. In the end, the solution ended up being to track on each node what is the maximum level it has received a force split object from. This allowed finding the objects that moved somewhere in the subtree when it was time to undo the force split of a higher node without having to scan the entire subtree below it.
With the forced splits in place, our plate stack now looks like this:

I recolored the plates to white so you can see the nodes more easily. We no longer have to search the entire stack for every query that gets close to it.
At this point though, what we made doesn't really resemble an octree anymore, so perhaps we should give it a new name. With the bounds stored on each node, it is structured similarly to a BVH, except it splits 8 ways on each level and uses the structure of an octree for determining where to split.
So I am calling it the OctoBVH.
OctoBVH vs Loose Octree
Now that we have both of these data structures implemented, we can make direct comparisons between both. Let's start with some visual ones for no purpose other than them looking pretty cool.






We can also compare the amount of intersection tests performed during the queries for loading bricks. To recap, these are the numbers for a loose octree:
- Brick Party (~2 million bricks): 2,103,969,999 tests
- North Pacific (~4 million bricks): 3,562,837,061 tests
- Midnight Alley (~4 million bricks): 4,878,939,315 tests
With the OctoBVH, we get significantly less useless intersection tests, and the entire loading process ends up being two times faster:
- Brick Party (~2 million bricks): 614,469,894 tests
- North Pacific (~4 million bricks): 902,968,082 tests
- Midnight Alley (~4 million bricks): 1,183,297,051 tests
OctoBVH Memory Layout
You can't think about a data structure without thinking about how you are going to store it in memory and what performance implications that would have.
The most immediate observation we can make is that while querying the tree, we typically either do not process the children of a node at all (i.e. if its bounds are outside the query) or process all the children (to find which overlap the query). This indicates that we should probably store the children together, in clusters of 8 nodes that are always processed as a block. Those children also have some common properties that are always the same, such as their height in the tree.
We are not going to create absurdly large trees, so it is fine to store all of the nodes in arrays and use 32 bit indices to refer to other ones.
Since we implemented the forced splits, the number of elements in a node is bounded. So there is no need to store dynamic arrays of elements per node, we can just make a struct to store the maximum number of element handles and then put this into another array. We won't need constant allocations for adding/removing objects from nodes this way. If a node has any elements, we can reference them with another 32 bit index.
Putting it all together, this is what I came up with:
struct FNodeCluster
{
PxVec3 BoundsMin[8]; // 96 // Min bounds for each node.
PxVec3 BoundsMax[8]; // 192 // Max bounds for each node.
uint32 ChildIndex[8]; // 224 // Pool index of cluster containing children for each node.
uint32 LeafIndex[8]; // 256 // Pool index of leaf containing elements for each node.
uint32 FilterBits[8]; // 288 // Filter bits used to accelerate queries for each node.
uint8 NumElements[8]; // 296 // Number of elements in leaf or 255 if overflowed for each node.
uint8 MaxMinLevel[8]; // 304 // Maximum min level of elements in subtree for each node.
uint32 ParentNodeIndex; // 308 // Index of parent node (pool index of cluster << 3 | node index).
uint32 NumSubtreeElements; // 312 // Total number of elements in this cluster and children.
uint32 NumParentOverflow; // 316 // Total number of elements forced in this cluster.
uint32 Level; // 320 // Level of these nodes. Width of the nodes is 1 << level.
};
struct FLeafElements
{
// Pool index of elements in the leaf.
uint32 Indices[OCTOBVH_MAX_INDICES_PER_LEAF];
};It takes only 40 bytes per node to store, which seems pretty good considering 24 of those are for the bounds. Accessing element bounds through the indices on the leaf takes an extra indirection, so I experimented with caching the bounds in this struct. Surprisingly, this brought zero performance improvement in real world tests, so I reverted it. The optimal number of elements per leaf appears to be 8.
Virtual Memory Pools
For large builds, we are going to have an absurd amount of node clusters, and even more actual bricks. How do we store these? The obvious solution is to use a dynamic array, but this incurs a massive hitch when we have to expand it to a larger allocation. Having no hitches from players placing additional bricks is an absolute requirement.
We could allocate the data in multiple chunks, so we don't have to move everything to add more node clusters. However, this means we can no longer nicely use our single 32 bit index to indirect into a pool array and would instead have to first figure out where the correct chunk is.
It turns out there is a more advanced solution! Modern operating systems let you explicitly request extremely large virtual memory regions without requiring the entire region to actually be backed by physical memory (in your ram slots) yet.
For example, on Windows, we can use the VirtualAlloc function to request an array of absurd size - such as one billion node clusters. This will give us a region of memory that has been locked down so nothing else can go inside, without actually taking up any real memory yet. Fancy!
We can then begin committing as many subregions as we need to store our nodes, so we essentially have a dynamic array again, but it never has to move during resizing! Perfect, that's what we wanted:

Of course, we can also decommit subregions again as our array shrinks. But what if people remove their bricks in the "wrong" order? Imagine we have a few thousand bricks at the very first indices, then 10 million empty slots that have been removed, and then a thousand bricks again. That would be a colossal waste of memory, and break player's expectations that memory usage goes back down.
Luckily, we can even decommit empty subregions from the middle of our massive array just fine. That would then look something like this:

With a bunch of extra logic for tracking empty slots and empty pages in free lists (which can be stored in the same memory region as the actual array) we now have a fully automatic memory pool that allows us to allocate any reasonable number of elements. It will automatically use more or less physical memory to store the data, elements never move in memory, and we can use stable 32 bit indices for everything. Very nice!
Virtual memory pools are now being used for bricks, OctoBVH nodes and leaves, collision instances, and several other internal arrays. They can be relatively easily extended to support "parallel" pools, using the same index to access multiple pooled things. You could also support multi threaded allocations using separate page chains per thread, etc. It's surprising that I had to implement this myself rather than a modern game engine already coming with something so useful.
OctoBVH Queries
We've finally created the perfect tree to contain our build, but what do we actually do with this? We haven't yet gotten to actually query it! As a reminder, these are the queries we have to support:
- Overlap (With both AABB and OBB)
- Raycast (Unlimited and limited distance)
- Sweep (Raycast with an oriented shape, either a box or sphere/capsule)
- Contact generation (Like overlap but with limited detail)
Overlap Query
There is really not much to write about overlap queries. You start from the root node, test if each child overlaps the query shape, if yes, recurse into those nodes. You could use a manual stack instead of recursion to speed it up slightly.
Raycast Query
The raycast is significantly more interesting, because there is big potential for a performance footgun. Namely, what do you do if asked to trace a ray across the entire build, but it should return a hit at a wall immediately in front of you? Do you pointlessly search through everything behind this wall too?
For example, imagine there was a hit in the green node. There would then not be any point in searching all of the red nodes that the ray also travels through.
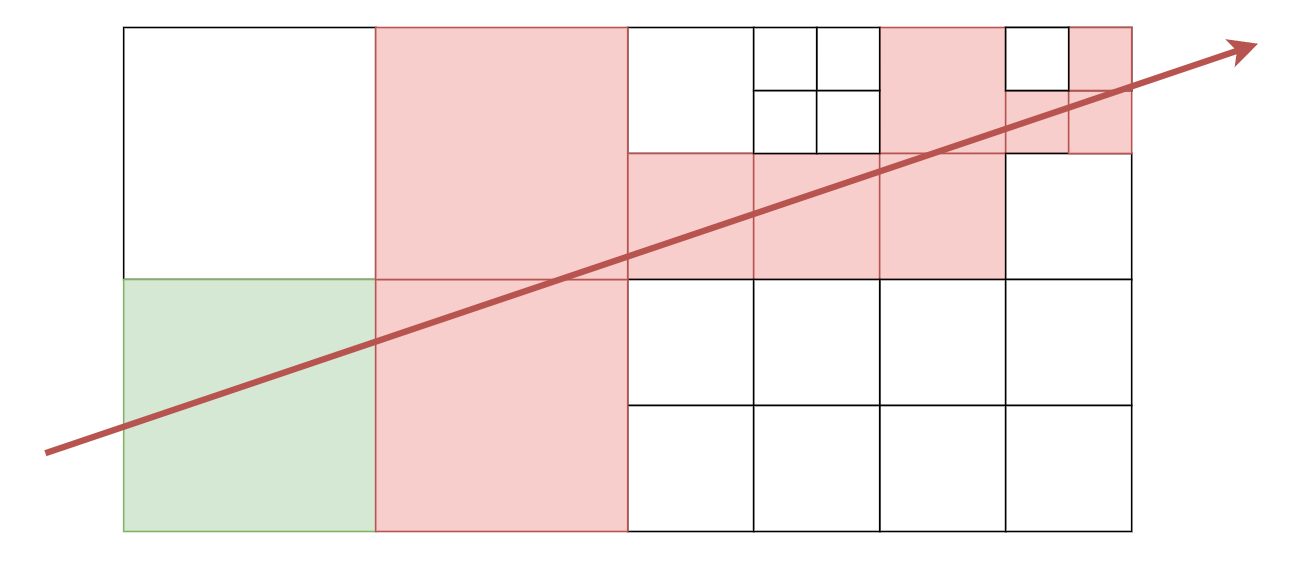
But how do we ensure that we always search the green node first, with our ray pointing in an arbitrary direction in the tree, at each level in the hierarchy?
The solution is to use the correct traversal order when recursing into child nodes. For example, if the ray is pointing towards positive X, we should search the octants with a lower X value for their center first.
After significant puzzling, I ended up with this function for determining the correct traversal order for a given ray direction. If this order is computed once at the start and used at every level, it will result in optimal traversal of the octree.
// Returns 8 uint8 indices of children to visit. Start from the lowest byte.
uint64 RayTraversalOrder(const PxVec3& Dir)
{
// Initial assumption: abs(x) >= abs(y) >= abs(z)
float Value[3] { Dir.x, Dir.y, Dir.z };
uint8 Axis[3] { 0, 1, 2 };
// We can sort three numbers in three flips to get most impactful axis.
if (FMath::Abs(Value[0]) < FMath::Abs(Value[1]))
{
Swap(Value[0], Value[1]);
Swap(Axis[0], Axis[1]);
}
if (FMath::Abs(Value[1]) < FMath::Abs(Value[2]))
{
Swap(Value[1], Value[2]);
Swap(Axis[1], Axis[2]);
}
if (FMath::Abs(Value[0]) < FMath::Abs(Value[1]))
{
Swap(Value[0], Value[1]);
Swap(Axis[0], Axis[1]);
}
// Now combine masks to build 8x uint8 array. For example, if our largest
// axis is X and it is negative, we will set to visit the 4 nodes with
// higher X position first by setting the X bit in the first 4 indices.
// If it is positive, we will set the X bit in the last 4 indices instead.
// Interleave this for all 3 axes.
uint64 Result = 0;
// First axis
if (Value[0] < 0.f)
Result |= 0x00'00'00'00'01'01'01'01 << Axis[0];
else
Result |= 0x01'01'01'01'00'00'00'00 << Axis[0];
// Second axis
if (Value[1] < 0.f)
Result |= 0x00'00'01'01'00'00'01'01 << Axis[1];
else
Result |= 0x01'01'00'00'01'01'00'00 << Axis[1];
// Third axis
if (Value[2] < 0.f)
Result |= 0x00'01'00'01'00'01'00'01 << Axis[2];
else
Result |= 0x01'00'01'00'01'00'01'00 << Axis[2];
return Result;
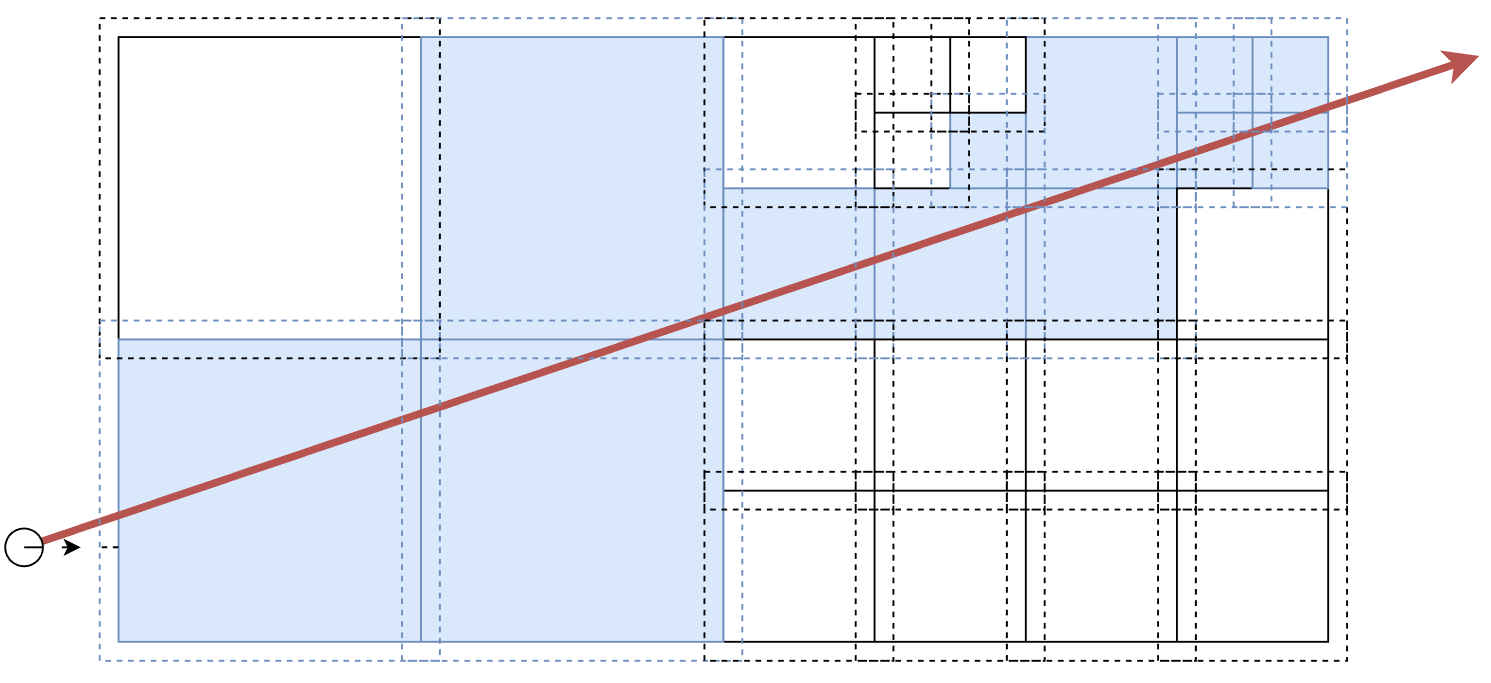
}We can visualize the effectiveness of using the correct traversal order by comparing some actual raycasts in the game with the function used normally and reversed as a counter example.
Imagine that a player is firing a raycast based weapon from the bottom right corner in this map here. He has pretty terrible aim though, hitting the scaffold.
For these, we'll use a different color key: grey are nodes that have been explored, black are nodes that have been processed but found outside the query, purple are elements that have been tested, and green is the element that was hit. Elements or nodes that were not processed are not shown.


You can imagine how using the incorrect traversal order would really destroy the performance of your raycast queries. The larger the map, the worse it gets.
We can also take this moment to appreciate the OctoBVH again. Let's compare a raycast along the path I showed earlier between the loose octree and OctoBVH:


Since that was so fun, one more across that tile floor:


Sweep Query
Sweeps are used mainly by players. Every tick, players will sweep a capsule against the world to figure out where they should walk or slide or collide with walls. Thus, it is critical that we support these.
Interestingly, we can simplify the sweep to a slightly modified raycast. All we have to do is increase the size of any bounding box we process by the radius of the shape being sweeped before testing it. There's not much else to it.
The same traversal order for the raycasts can also be used for the sweeps.
Contact Generation
Finally, we are getting to the interesting part! Though, since we are implementing a custom shape within PhysX, there is actually not that much to it, PhysX already provides implementations of contact generation for every primitive shape.
We start by doing an overlap query against the OctoBVH to find elements that are near the other shape, call the correct contact generation functions for each one, and finally transform the contacts back to global space. Yes, this will generate an absurd amount of contact points when a shape is sliding across a detailed floor.
Here are some examples of the contact points generated for things colliding with a bunch of bricks:


Sometimes we will have fairly large shapes colliding against a far too detailed build with tons of micro bricks, so we can also limit the detail involved in the collision here. For example, if an entire subtree is smaller than 1/16 the size of the incoming shape, we probably don't care about what's inside - and simply pretend it was a solid box based on its bounds.
Collision for Editable Structures
So we now have a custom shape that we can move around, which lets other primitives collide with the bricks inside. What do we do though, if that other shape is also a structure made from bricks? We can't just try to detect collisions against every brick in it, that would be far too slow.
Let's recap the goals:
- We want to be able to have things like cargo inside a space ship inside a space station, bricks inside a container, crates on the bed of a truck, etc.
- We don't necessarily need "perfect" collision such as being able to mesh multiple large gears built from bricks. Two-way concave collisions weren't in the plan from the start.
We can achieve this by replacing the smaller of the two grids with a convex shape and then colliding this one with the bricks inside the other. For example, crates would be replaced by a box and collide with the bricks of the truck. The truck itself would be replaced by a convex shape when driving it onto a ship.
How do we generate this convex shape though? The vehicle might be made from a hundred thousand bricks, and we don't want to hitch when it has to be updated.
Convex Approximation From OctoBVH
It turns out there is a straight forward solution: we simply don't consider all bricks for the convex generation. If we want a very rough collider around a house on wheels, the highly detailed micro brick toilet probably doesn't change the result.
Instead, we'll start from the root of the OctoBVH and traverse down a small number of levels, collecting any huge bricks we encounter along the way. Then we also collect all the bounds of remaining subtrees at that level. Convert these boxes and convexes to points and pass it off to the convex generator in PhysX. Soon after, we'll have a new convex that roughly approximates our vehicle!
Convex Simplification to Box
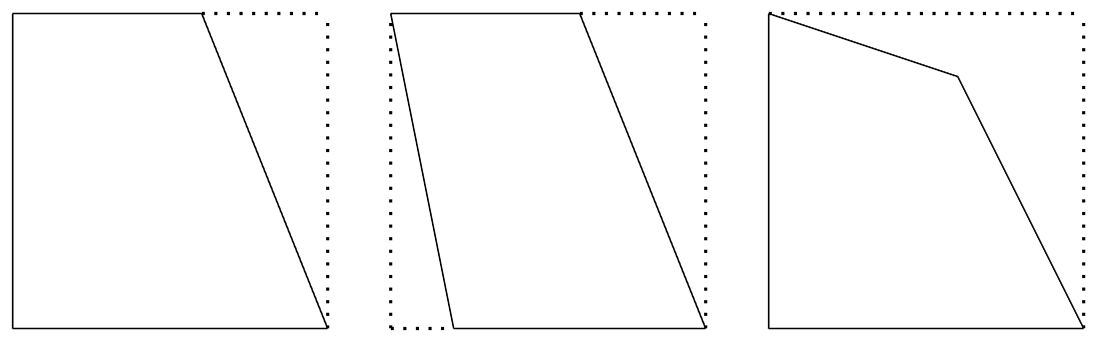
Colliding many convex shapes is still fairly slow. In some cases, we are able to swap the convex for an equivalent box. For example, if you build a cube, or come up with the great idea of having individual bricks as vehicles. This check is really simple, just have to check if the newly generated convex happens to have exactly 8 corners which lie exactly on each of the corners of its bounding box.
It is important to verify that all 8 corners of the bounding box are present, otherwise a wedge shape could be misinterpreted as a cube. For a 2D example, these shapes all have 4 corners, but they are not rectangles:
Results for Real World Builds
The results look like this for small objects:


Or slightly larger objects:

The convex generation also works for larger objects. You can see how this one is a bit inaccurate around the corners because we stopped processing subtrees.




Due to the limited collision detail in the contact generation query, we can cover the map in large objects without causing significantly more overhead than the same number of small objects would.


As long as the objects keep getting smaller, there isn't really a limit to how much stuff we can stack with reasonable detail.

Fixing Unreal Engine Performance
The first time I tried spawning an absurd amount of physics objects with multiple materials, lots of lights and other doodads attached, I was surprised by just how terribly the game was running. It was almost unplayable on my computer. Well, that is probably because of the thousands of moving lights, but still.
Let's open the game in a profiler and find out what the problem is. I use the awesome Superluminal here. Unreal Engine comes with its own profiler, but it is exclusively instrumentation based - which means it is often very inaccurate when dealing with many small zones such as Unreal Engine processing lots of physics objects. Superluminal gives us way more useful information too.
The extent of the terrible performance out of the box is just shocking. What is the engine even doing here? Time to unpack this and fix it as much as we can.
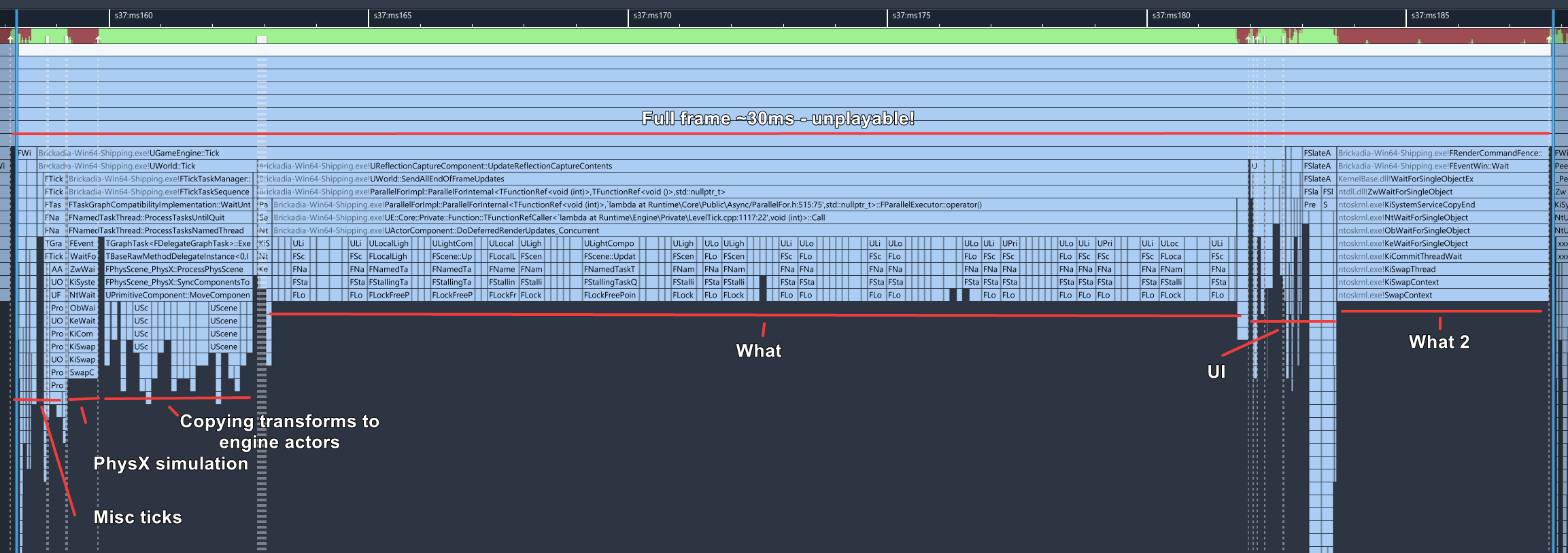
Batching Render Transform Updates
Now, we certainly seem to have our work cut out for us. Most of the disastrous performance is coming for a single function doing something for quite a long time. We'll want to focus on the section I fittingly titled "What" above first.
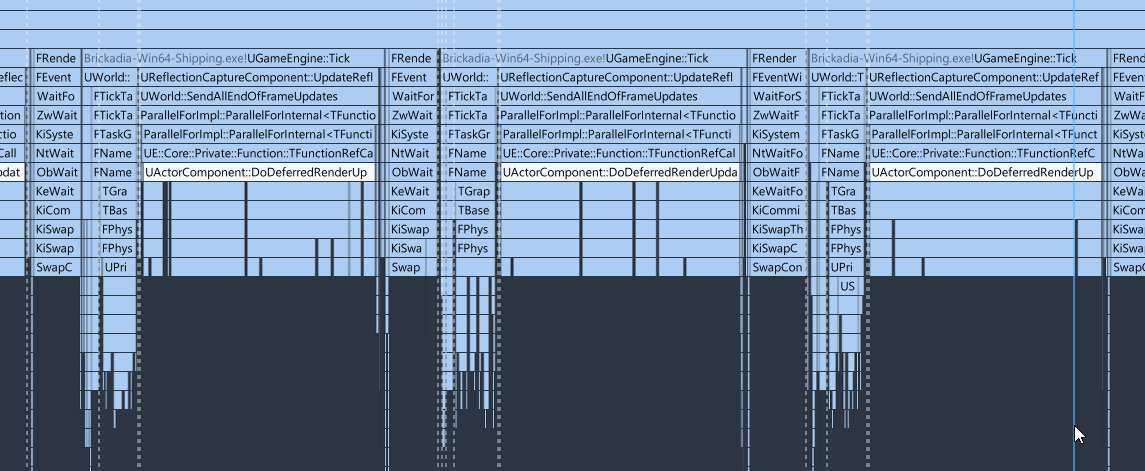
Let's start drilling down. I selected a reasonably large amount of frames so we get more accurate timings from having more samples.
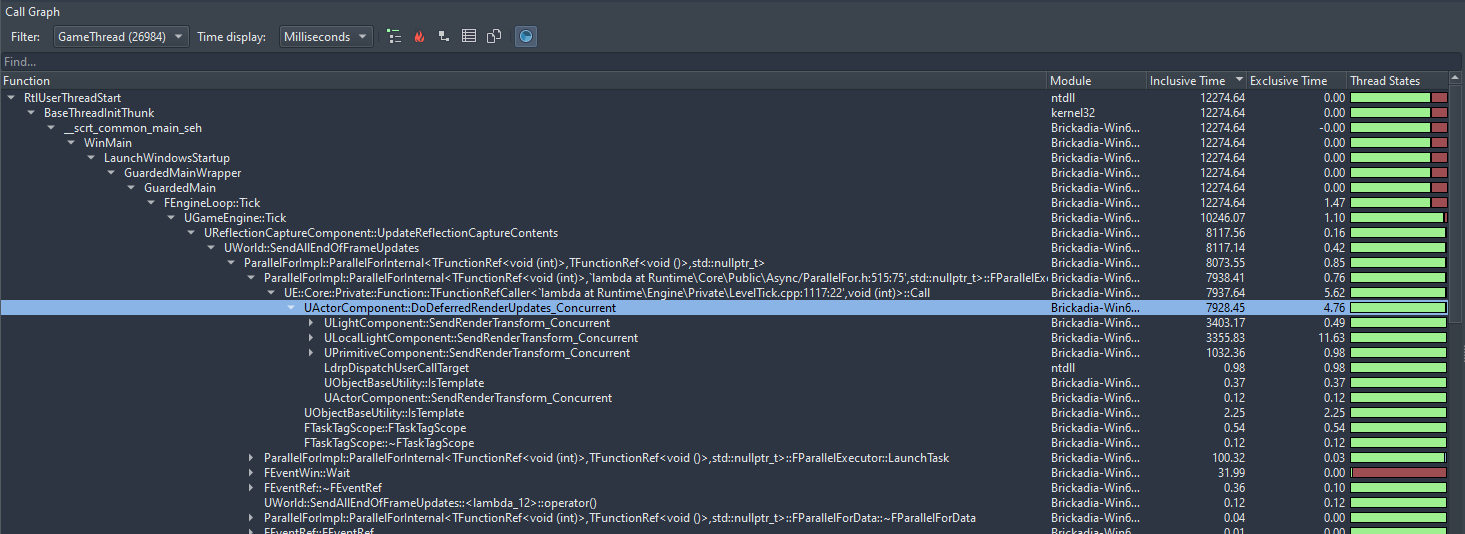
We can see that almost all the time is being spent in SendRenderTransform functions. Let's explore these further to see what is going on here.

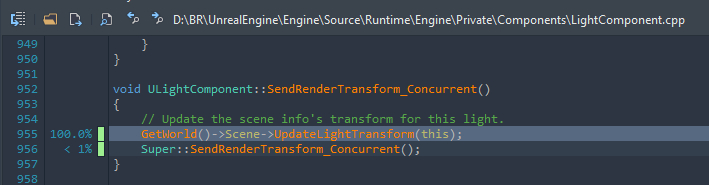
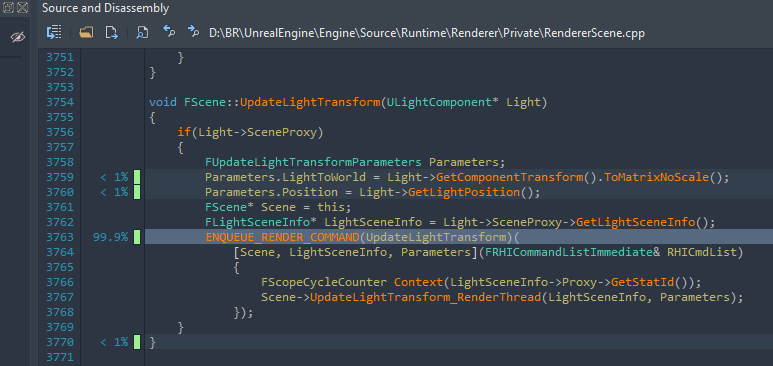
We can explore the second function too, but it appears to be more of the same. There is one question though, why are we even updating the light radius every frame at all, considering we merely moved the light?

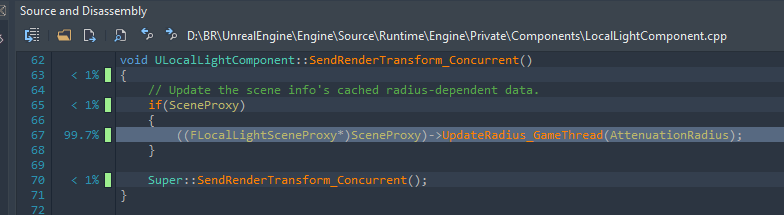
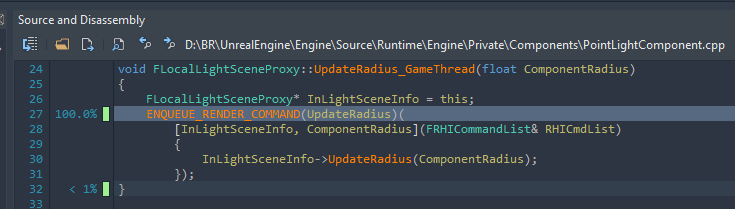
There is something even more disturbing going on though, if we zoom out to the thread overview! The blue marked area is where our DoDeferredRenderUpdates function is executing on the main thread.
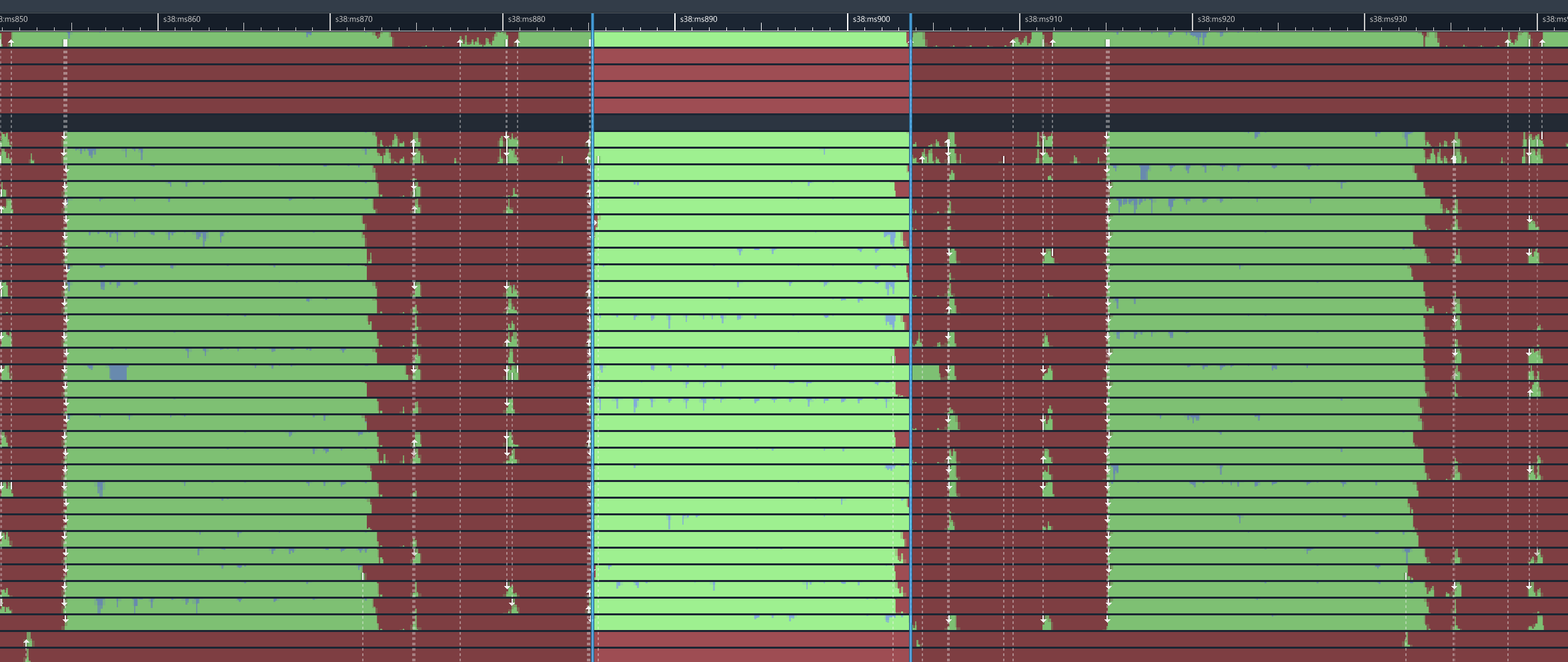
Now, at this point it's pretty clear what happened. Someone must have noticed that sending all these individual render transform update commands was very slow, so they decided to fix it by putting a parallel for around it. This makes some sense, to the extent that we can prepare the updates in parallel. However, it is completely ignoring the fact that you cannot actually sensibly enqueue render commands from multiple threads at the same time.
I think we should try to improve this. What we'll do is keep their parallel for, but instead of enqueueing render commands directly, we'll simply push updated transforms to an atomic increment array. Then, at the end of the frame, send all of these as a single render command. Also, we'll get rid of the light radius update.
Let's start by creating a new console variable so we can toggle this change and compare performance before and after.
static TAutoConsoleVariable<int32> CVarBatchedRenderThreadTransformUpdate(
TEXT("r.BatchedRenderThreadTransformUpdate"),
0,
TEXT("0: send individual render commands for transform updates.\n")
TEXT("1: merge all transform updates into a single render command."));Then, we'll implement this array so we can add elements from inside the parallel for. We only need a small subset of the array functionality to actually work.
#pragma once
#include "CoreTypes.h"
#include "Containers/Array.h"
#include "HAL/PlatformAtomics.h"
/**
* An array that can be added to from multiple threads without locks.
*/
template<typename InElementType, typename InAllocatorType = FDefaultAllocator>
class TAtomicAddArray : public TArray<InElementType, InAllocatorType>
{
public:
typedef typename InAllocatorType::SizeType SizeType;
typedef InElementType ElementType;
typedef InAllocatorType AllocatorType;
FORCEINLINE SizeType AtomicAddUninitialized(SizeType Count = 1)
{
// You must pre-size the array correctly or this will fail.
return FPlatformAtomics::InterlockedAdd(&this->ArrayNum, Count);
}
template <typename... ArgsType>
FORCEINLINE SizeType AtomicEmplace(ArgsType&&... Args)
{
SizeType Index = AtomicAddUninitialized();
new(this->GetData() + Index) ElementType(Forward<ArgsType>(Args)...);
return Index;
}
FORCEINLINE SizeType AtomicAdd(ElementType&& Item)
{
CheckAddress(&Item);
return AtomicEmplace(MoveTempIfPossible(Item));
}
FORCEINLINE SizeType AtomicAdd(const ElementType& Item)
{
CheckAddress(&Item);
return AtomicEmplace(Item);
}
};
Then we can use it to create arrays of transform updates to send each frame. I just added these in a somewhat random place in FScene, capturing all variables that were previously included in the individual render commands.
struct FPrimitiveTransformUpdateParams
{
FPrimitiveSceneProxy* PrimitiveSceneProxy;
FBoxSphereBounds WorldBounds;
FBoxSphereBounds LocalBounds;
FMatrix LocalToWorld;
TOptional<FTransform> PreviousTransform;
FVector AttachmentRootPosition;
};
struct FLightTransformUpdateParams
{
FLightSceneInfo* LightSceneInfo;
FMatrix LightToWorld;
FVector4 Position;
};
TAtomicAddArray<FPrimitiveTransformUpdateParams> PendingPrimitiveTransformUpdateBatch;
TAtomicAddArray<FLightTransformUpdateParams> PendingLightTransformUpdateBatch;As mentioned previously, we'll need to pre-size these arrays correctly or crash.
void FScene::PreparePrimitiveTransformUpdate(int32 Slack)
{
if (CVarBatchedRenderThreadTransformUpdate.GetValueOnAnyThread())
{
PendingPrimitiveTransformUpdateBatch.Empty(Slack);
PendingLightTransformUpdateBatch.Empty(Slack);
}
}We can insert a call to this function before the parallel work in UWorld::SendAllEndOfFrameUpdates, where the max count is already known.
...
if (Scene)
{
Scene->PreparePrimitiveTransformUpdate(
LocalComponentsThatNeedEndOfFrameUpdate.Num() +
ComponentsThatNeedEndOfFrameUpdate_OnGameThread.Num());
}
auto ParallelWork = [IsUsingParallelNotifyEvents](int32 Index)
{
TRACE_CPUPROFILER_EVENT_SCOPE(DeferredRenderUpdates);
...Now we need to actually store those transform updates. We can modify FScene::UpdatePrimitiveTransform and FScene::UpdateLightTransform to do this, notice the new code calling AtomicAdd on our array.
...
if (bPerformUpdate)
{
if (CVarBatchedRenderThreadTransformUpdate.GetValueOnAnyThread())
{
PendingPrimitiveTransformUpdateBatch.AtomicAdd(UpdateParams);
}
else
{
FScene* Scene = this;
ENQUEUE_RENDER_COMMAND(UpdateTransformCommand)(
[UpdateParams, Scene](FRHICommandListImmediate& RHICmdList)
{
...void FScene::UpdateLightTransform(ULightComponent* Light)
{
if (Light->SceneProxy)
{
FLightTransformUpdateParams Params;
Params.LightSceneInfo = Light->SceneProxy->GetLightSceneInfo();
Params.LightToWorld = Light->GetComponentTransform().ToMatrixNoScale();
Params.Position = Light->GetLightPosition();
if (CVarBatchedRenderThreadTransformUpdate.GetValueOnAnyThread())
{
PendingLightTransformUpdateBatch.AtomicAdd(Params);
}
else
{
FScene* Scene = this;
ENQUEUE_RENDER_COMMAND(UpdateLightTransform)(
[Params, Scene](FRHICommandListImmediate& RHICmdList)
{
...Finally, to finish this off, we need to send the updates we prepared in our arrays as a single render command at the end of UWorld::SendAllEndOfFrameUpdates.
void FScene::CommitPrimitiveTransformUpdate()
{
if (CVarBatchedRenderThreadTransformUpdate.GetValueOnAnyThread())
{
FScene* Scene = this;
if (PendingPrimitiveTransformUpdateBatch.Num())
{
ENQUEUE_RENDER_COMMAND(CommitPrimitiveTransformUpdate)(
[Batch = MoveTemp(PendingPrimitiveTransformUpdateBatch), Scene](FRHICommandListImmediate& RHICmdList) mutable
{
for (auto& UpdateParams : Batch)
{
Scene->UpdatePrimitiveTransform_RenderThread(
UpdateParams.PrimitiveSceneProxy,
UpdateParams.WorldBounds,
UpdateParams.LocalBounds,
UpdateParams.LocalToWorld,
UpdateParams.AttachmentRootPosition,
UpdateParams.PreviousTransform
);
}
}
);
}
if (PendingLightTransformUpdateBatch.Num())
{
ENQUEUE_RENDER_COMMAND(CommitLightTransformUpdate)(
[Batch = MoveTemp(PendingLightTransformUpdateBatch), Scene](FRHICommandListImmediate& RHICmdList) mutable
{
for (auto& UpdateParams : Batch)
{
Scene->UpdateLightTransform_RenderThread(UpdateParams.LightSceneInfo, UpdateParams);
}
}
);
}
}
}Let's profile the game again and see if the performance improved.
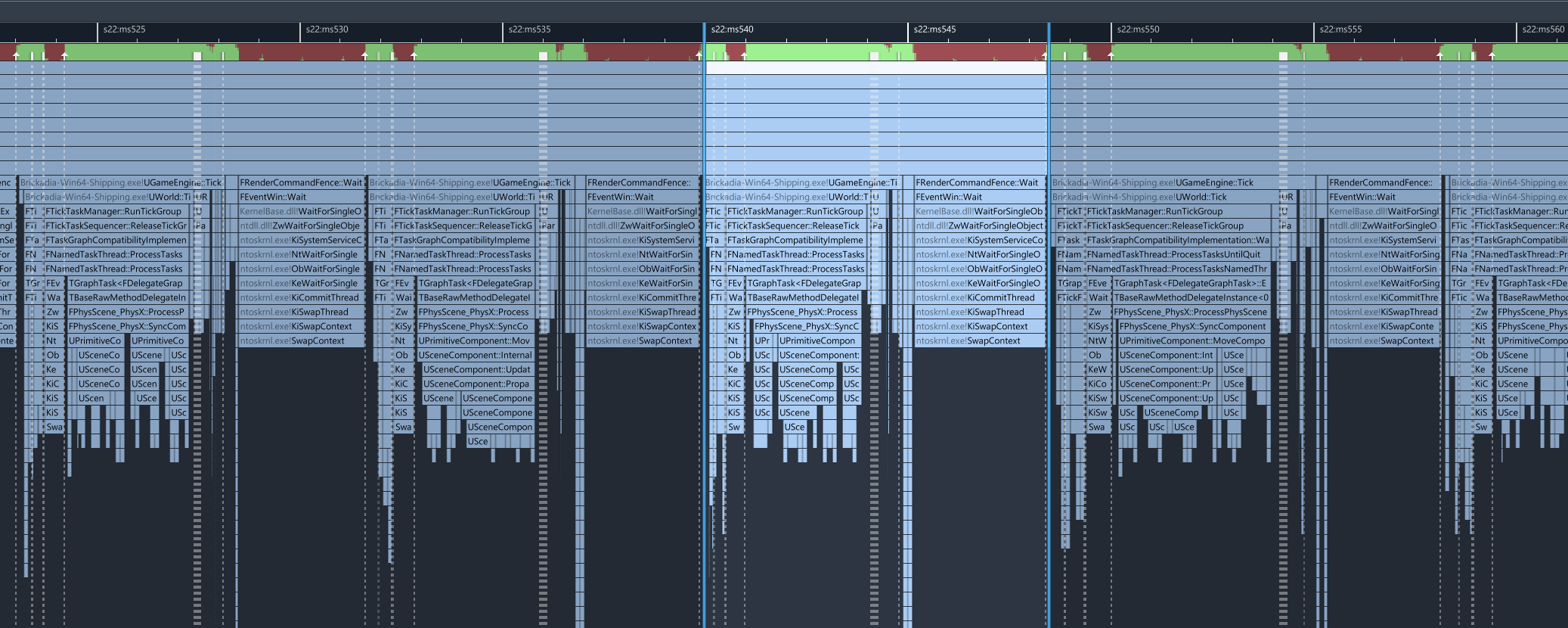

Yes! In fact, this single change has brought our frame time down from ~30ms to ~8ms. We're now running at 120 fps. That's quite the upgrade for such a small change, typically it would be much harder to achieve such an improvement.
There are more things we can fix though.
Speeding up MoveComponent
Next, we could focus on the part where the engine updates the actor transforms to match PhysX. That also seems to be quite slow.
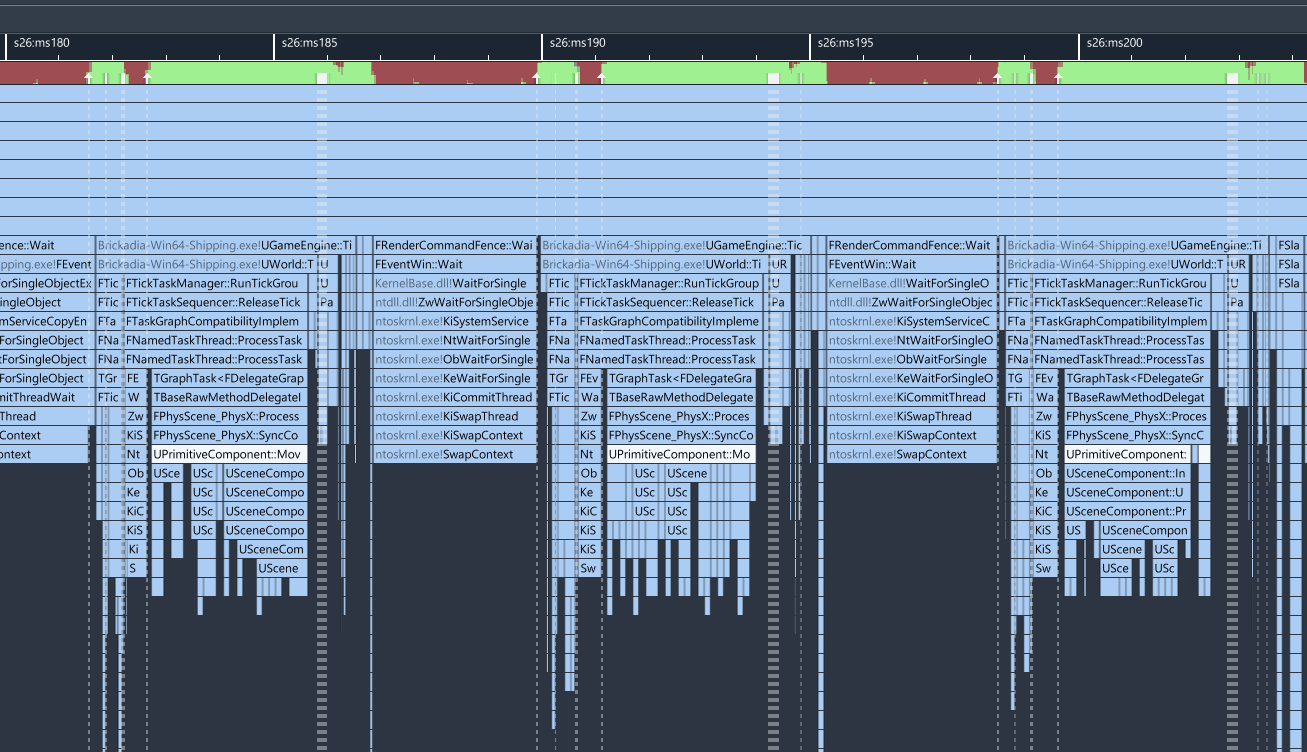
If we drill down here, we can see some problems - for a start, we are unnecessarily updating overlaps. This is probably because there is an item spawn attached to the vehicle I spawned a bunch of. There's no point in this running, so let's get rid of it completely.

Under the SetWorldLocationAndRotation we can also find a few inefficient things: we are pointlessly computing bounds of brick render components (they already get updated at the end of the frame), and for some reason Unreal Engine 5 is not compiling with AVX2 instructions by default despite having lots of special code paths for their double precision math on positions, bounds, etc. Only expecting minor improvements at best here though.

Indeed that does give us a small improvement in the game thread time - we are now spending a bit less in MoveComponent compared to the whole frame:
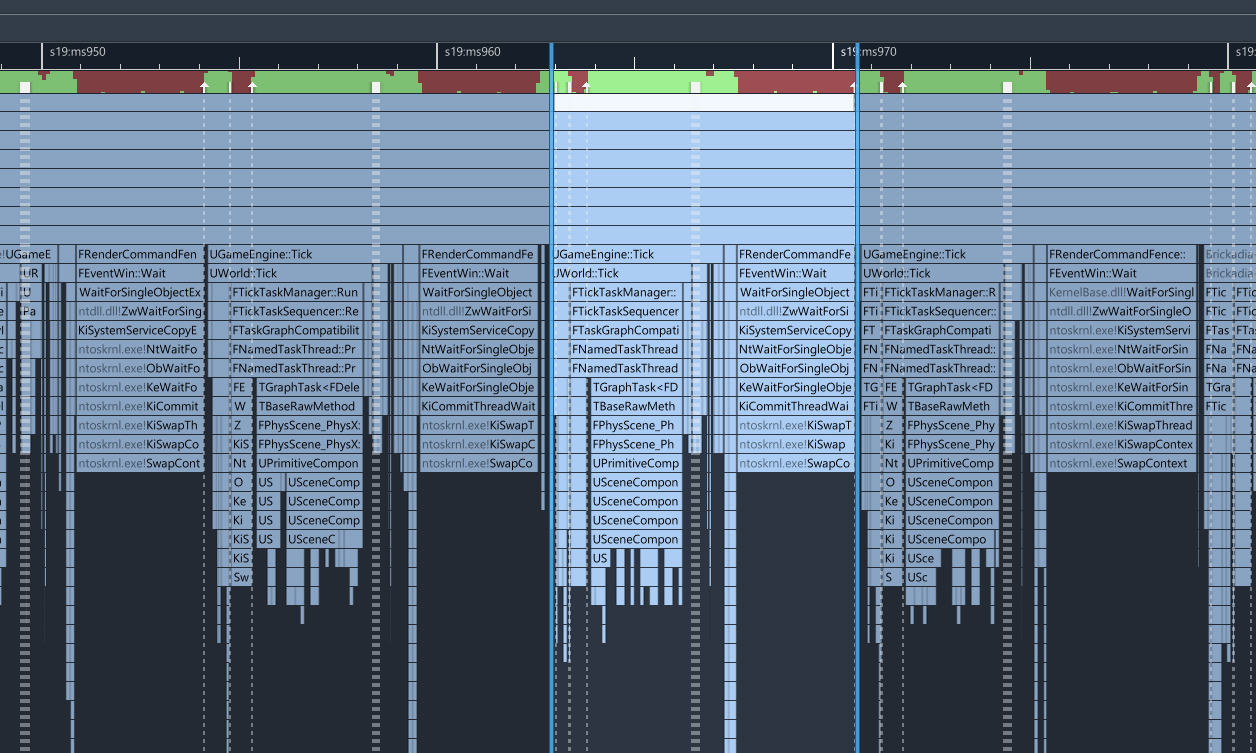
That's still really slow. If it wasn't so sad, it would be funny how the component system is such a big mess of chasing object indirections that it often takes longer to copy the transforms than running the entire physics simulation. I'd like to improve this one day with a data oriented parallel transform update.
There's a problem though... we're not actually making the game run faster at this point. You can see how we're already spending an entire half of the frame just waiting for the render thread to do things. Unfortunately, we do not have infinite time for optimizing this, and all good things must eventually come to an end, so here is where I stopped for now. Some other day I will come back to see if we can't make the render thread run faster too.
Very happy with the overall 30 fps -> 120 fps upgrade in this particular scene!
Extra Goodies
This custom collision refactor changed a ton of internal stuff for bricks, so I'm happy to report that the performance of the game has significantly improved in several other places.
Faster Brick Loading
For a start, it is now faster to load large builds!






Reduced Return to Menu Delay
Some players reported an annoyingly long time spent returning to main menu after leaving a server with a large amount of bricks. This delay no longer exists, took just half a second to exit out of Midnight Alley.
Reduced Client Memory Usage
The memory usage of the client has been significantly reduced. In Alpha 5 Patch 6, we get these values for the 3 builds above:
- Brick Party: 4.1 GB
- North Pacific: 5.0 GB
- Midnight Alley: 6.0 GB
Loading the same builds in the new version of the game:
- Brick Party: 2.1 GB
- North Pacific: 2.4 GB
- Midnight Alley: 2.8 GB
Reduced Server Memory Usage
The memory usage of dedicated servers has been significantly reduced aswell. In Alpha 5 Patch 6, we get these values for the 3 builds above:
- Brick Party: 3.4 GB
- North Pacific: 4.5 GB
- Midnight Alley: 5.2 GB
Loading the same builds in the new version of the game:
- Brick Party: 1.0 GB
- North Pacific: 1.3 GB
- Midnight Alley: 1.5 GB
What's Next for Brickadia?
We're not done with physics yet. Not even by a long shot! There's a lot more to come before we can have the physics based sandbox we dreamed of, such as:
- Physics replication. The physics demo at the start of this post was recorded as the host of a server, it did not look quite as good on clients. That's because the physics replication system that comes with Unreal Engine is frankly terrible. We'll be throwing this out and writing a better one soon. A future tech blog post to come here.
- A better way to place joints in the game, and I also want to investigate using articulations for jointed contraptions, though for now the basic joints work well enough.
- Proper control over vehicles and joints, such as actually driving a car using motorized wheels or flying a space ship using thrusters. These will be integrated with our wire logic system to allow customizable controls. Likely there will be another blog post on this in the future.
- Saving and loading complex prefabs such as a vehicle with its wheels or other physics contraptions. Current save files still only contain a single brick grid, which makes it quite clunky to play with this stuff.
If you got all the way to the end of this post, I hope you enjoyed it! Physics is only one of the major engineering projects going on behind the scenes at Brickadia. We'll likely also have something more to show on Behaviors scripting soon.